안녕하세요!
이번 글은 5/23(목)에 오프라인으로 진행된 데보션 Kafka 밋업 후기인데요.
오랜만에 데보션 영 발대식 때 갔던 장소를 가니 감회가 새로웠습니다ㅎㅎ
급하게 가서 사진을 못찍었는데 맛있는 간식과 커피가 구비되어있어서 너무 좋았어요..
(특히 감자칩이랑 말랑카우 넘 맛있게 먹었습니다🥰)
일단 Kafka에 대해 말하자면, 저에겐 아직 생소한 개념이었어요.
물론 최근 졸업 프로젝트에서 사용할 스택을 조사해보다가 스쳐지나가듯 본 적은 있지만..
결국 Redis를 채택하면서 Kafka에 대해 깊게 알아볼 기회가 없었습니다.
이런 상황에 데보션에서 Kafka 밋업을 진행한다고 하니 기대되는 마음으로 신청하게 되었네요!!😊
✨ “이커머스 환경에서의 카프카 클러스터 구축기” - 심재민 님

우선 심재민님의 세션은 3가지 클러스터를 기준으로 진행되었는데요.
1. 주문 클러스터
2. 검색 클러스터
3. 공용 클러스터
📌 주문 클러스터
이 파트에서는 Kafka를 선택한 이유에 대해서 간단히 들어볼 수 있었습니다.
먼저 기존 방식에 비해 1) 높은 DB 의존성 방지, 2) 높은 트래픽으로 인한 대기열 이탈 문제 방지, 3) 이벤트 활용이 가능하다는 장점이 있습니다.
DB 앞단에 요청을 처리하는 완충 장치를 두어 DB 부하에 따른 장애 위험을 감소시키고, 요청 분산을 통한 구매자 이탈 방지를 하기 위해서 채택하게 되었다고 합니다!🙌
그리고, Kafka 클러스터 중에서도 여러 종류가 있는데 1) 고객 데이터 관리를 용이하게 하고, 2) 일관성을 유지하기 위해 ‘Stretched Kafka Cluster’를 선택했다고 하셨습니다.
물론 이러한 ‘Stretched Kafka Cluster’에 장점만 있는 것은 아니였는데요. 이 구조는 각자의 클러스터로 뜨게 되는 현상인 IDC단절이 발생하는데, 이를 보완하기 위해 ‘DR 테스트’를 진행하셨다고 합니다.
심재민님의 도전 정신과 꼼꼼함을 엿볼 수 있는 파트였네요..!

📌 검색 클러스터
사실 검색 클러스터부터 조금 어려운 느낌을 받았는데요..😢
제가 이해한 바로는 메시지 브로커가 모든 검색 노드로 Broadcasting 하는데, 토픽 수준으로 샤딩 되어있어 이걸 보완하기 위해 ‘2 IDC Stretched Cluster’를 도입했다! 정도 얻어간 것 같습니다!
📌 공용 클러스터
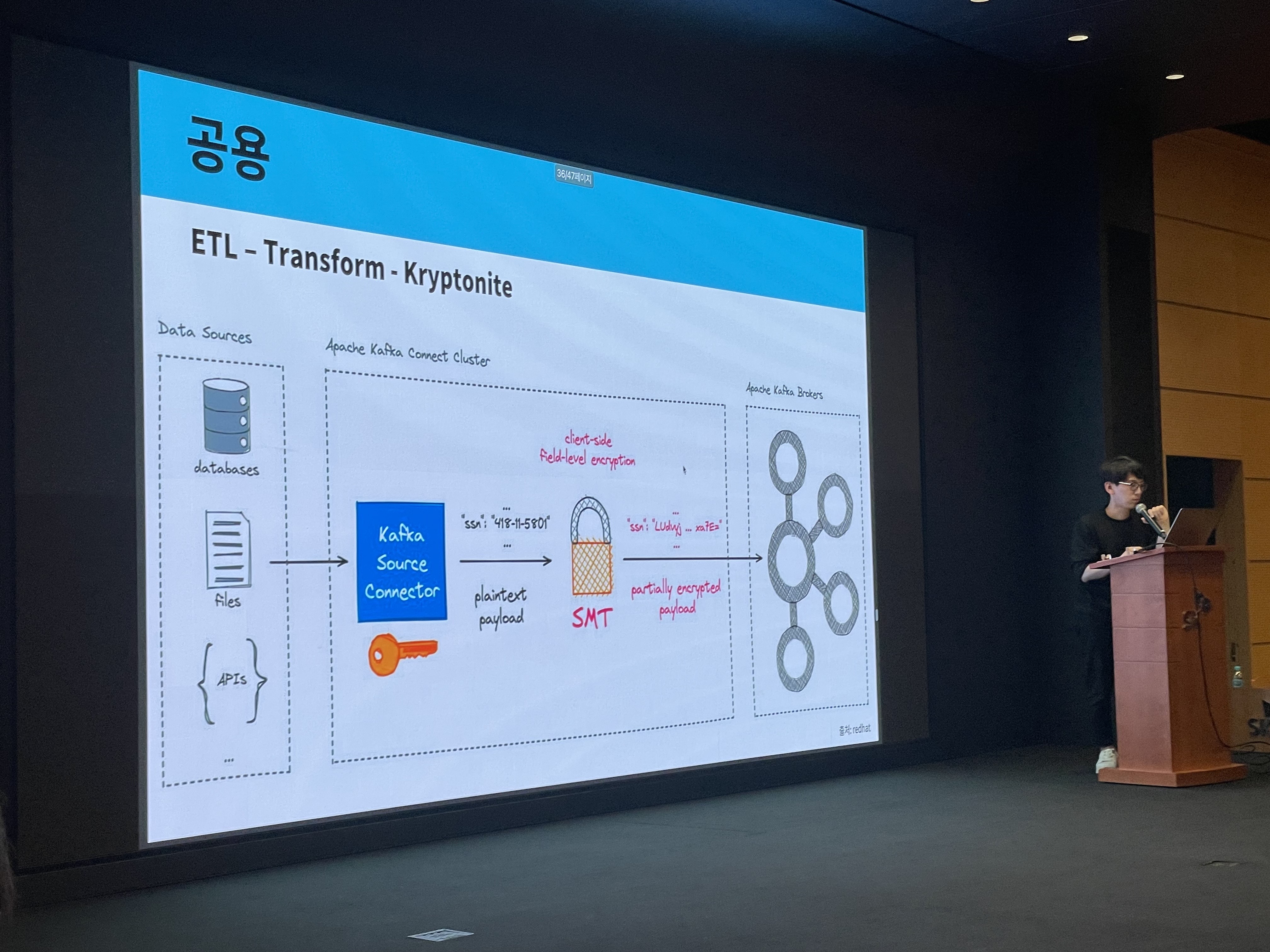
마지막으로 공용 클러스터의 경우 Kafka를 ETL로 활용하셨다고 합니다. 여기서는 보안 이슈가 중요하기 때문에 메시지를 실을 때 링크드인의 ‘Kryptonite 암호화’를 사용하셨다고 합니다!
✨ “Kafka 생태계에서 protobuf 사용하기” - 이동진 님

이 세션에서는 새로운 지식을 많이 알게되었는데요!
우선, Kafka의 경우 (key, value)로 저장되지만 내용물에는 관심이 없어 그저 byte 뭉치로 serialize/deserialize 한다는 것을 알게 되었습니다.
그리고, json 문자열로 직렬화하는 것이 생각보다 좋지 않다는 것도 처음 알게되었네요!
이번 졸업 프로젝트에서 Redis긴 하지만 json 직렬화를 많이 썼거든요. 생각보다 성능이 안좋다는 것을 알게 되어 조금 충격을 받았습니다ㅎ.. (리팩토링을 해야하나..😱)
어쨌거나 위와 같은 이유로 json이 아닌 Confluent Schema Registry + Avro가 오랫동안 표준이었다고 합니다.
🤔 그렇다면 표준이 된 이유는 다른 시스템보다 더 좋았기 때문일까요?
정답은 “그렇지만은 않다” 입니다!
우선 Avro와 Protobuf에 대해 성능 테스트를 진행했을 때 Protobuf가 더 우수했다는 조사 결과가 있었습니다.
(+ Avro는 데이터 덩어리만 저장되기 때문에 스키마가 없으면 이게 무슨 데이터인지 절대 알 수가 없는 단점이 있음)
그렇다면 왜 표준이 되었느냐! 라고 한다면, Confluent Schema Registry가 5.5 버전 이전까지는 Avro만 지원했기 때문입니다. 5.5 버전 이후로는 Protobuf도 지원이 되었고, 링크드인이 내부 직렬화 프레임워크를 Protobuf로 통일하게 되었습니다!
마지막으로 Schema Registry 구현체를 추천해주셨는데, 기억에 남는 것은 ‘Redhat APICurio’ 였습니다! 1) Debezium과의 연동이 가능하고, 2) Kafka 이외에도 다양한 저장소를 지원한다는 장점이 있었습니다. 제가 사용할 일이 생길지는 모르겠지만.. Kafka 고수이신 이동진 님이 추천해주신거니까 꼭 기억하고 있으려구요..ㅎㅎ
생소한 개념이 많았던 세션이었지만, 그렇기 때문에 더 신선하고 재밌게 들었던 것 같습니다!
(앞으로 배울게 한참 남았다는 기대감 같은거려나요..ㅎ)